Las GPU de NVIDIA han monopolizado el 90% de la cuota de mercado. En el sector de la IA, Jensen Huang está a un paso de conseguir un trono duradero: la tecnología de las comunicaciones. Si bien Estados Unidos y la Unión Europea han reconocido la gravedad de esta situación, solo China tiene actualmente la capacidad y la determinación para desafiar su dominio.
Academia china, 16 de Diciembre de 2024

El 9 de diciembre, China inició una investigación antimonopolio contra el fabricante de chips estadounidense Nvidia. La empresa podría enfrentarse a multas de hasta 1.030 millones de dólares, según el South China Morning Post.
Global Times informó que la investigación se centra principalmente en una adquisición. En 2019, Nvidia anunció la adquisición de Mellanox Technologies por 6.900 millones de dólares, la mayor operación de adquisición de ese año. La preocupación era que la compra de Mellanox por parte de Nvidia le permitiría completar un cuasimonopolio en la industria de la inteligencia artificial, un mercado que la Administración de Comercio Internacional de Estados Unidos estimó que agregará 15 billones de dólares a la economía global para 2030, lo que también atrajo el escrutinio de las autoridades antimonopolio de la Unión Europea y Estados Unidos. Sin embargo, parece que China es el único país que ha detenido el monopolio de Nvidia.
Para entender por qué, primero debemos comprender cómo funciona el monopolio de Nvidia:
Para entrenar una IA competitiva, son esenciales tres componentes básicos: hardware, software y tecnología de comunicación. Nvidia ha establecido un monopolio global sobre los dos primeros.
En términos de hardware, el H100 de Nvidia es actualmente el chip de entrenamiento de IA más vendido en todo el mundo. Según Nasdaq, Nvidia vendió GPU H100 por un valor estimado de 38 mil millones de dólares en 2023, ya que las empresas se apresuraron a adquirir los chips para entrenar modelos de lenguaje de gran tamaño. Este aumento de la demanda impulsó a Nvidia a la vanguardia del mercado de chips de IA, asegurándose una participación de mercado de más del 90%.

Mizuho Securities estima que Nvidia controla entre el 70% y el 95% del mercado de chips de IA, específicamente para entrenar e implementar modelos como el GPT de OpenAI. El H100, cuando se compra directamente a Nvidia, tiene un precio de aproximadamente 25.000 dólares. El poder de fijación de precios de Nvidia se refleja en un notable margen bruto del 78%, lo que demuestra claramente cuánto explota Nvidia a las empresas de tecnología después de obtener una posición de monopolio.
En términos de software, la ventaja competitiva más formidable de Nvidia es la Arquitectura de Dispositivo Unificado de Computación (CUDA).
La competencia por los modelos de IA surgió inicialmente de la rivalidad entre Google y Meta. Los ingenieros descubrieron que, si bien las CPU se destacan en la computación general y cumplen con los requisitos para las tareas de inferencia en IA, no eran suficientes para manejar las tareas de computación paralela a gran escala requeridas para el aprendizaje profundo, especialmente para entrenar modelos grandes. Las GPU, con sus poderosas capacidades de procesamiento paralelo, eran más adecuadas para este propósito. Sin embargo, sus modelos de programación y patrones de acceso a la memoria diferían significativamente de los de las CPU, lo que creaba desafíos de desarrollo considerables.
Para solucionar este problema, Nvidia introdujo CUDA en 2007, lo que permitió a los desarrolladores utilizar C/C++ para aprovechar la potencia de procesamiento en paralelo de las GPU para cargas de trabajo no gráficas. Esta innovación sentó las bases para el aprendizaje profundo, lo que impulsó a importantes frameworks como TensorFlow y PyTorch a integrar soporte nativo para CUDA desde el principio.
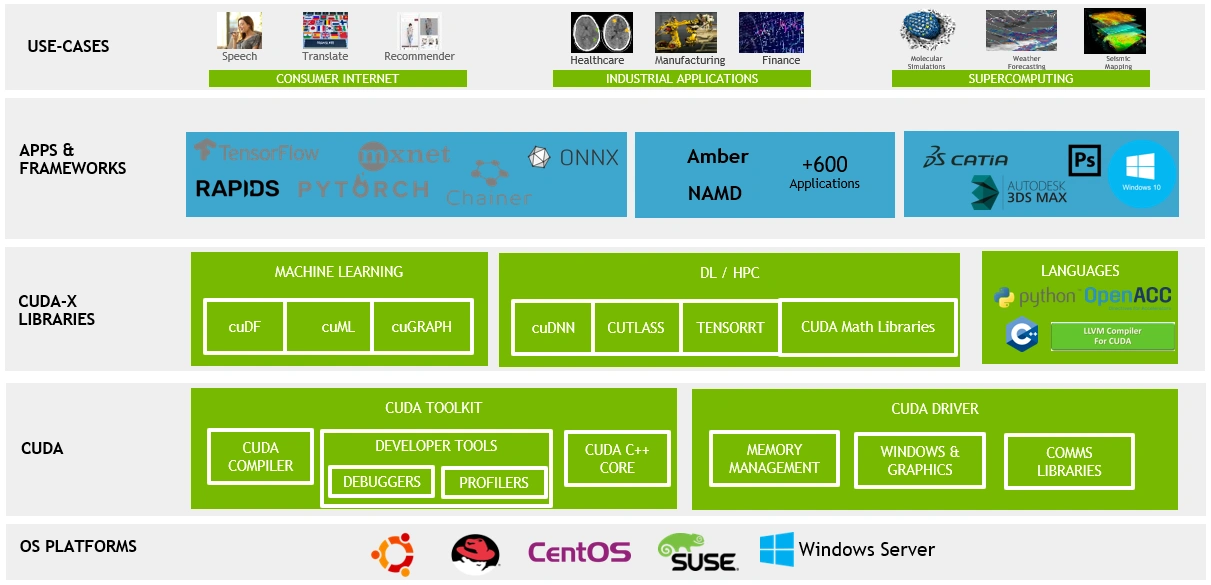 CUDA se convirtió rápidamente en la forma más eficiente de aprovechar la potencia computacional de las GPU. Según el blog de tecnología de Netflix, al utilizar un núcleo CUDA personalizado, el tiempo de entrenamiento de una red neuronal en una instancia cg1 se redujo de más de 20 horas a solo 47 minutos al procesar 4 millones de muestras.
CUDA se convirtió rápidamente en la forma más eficiente de aprovechar la potencia computacional de las GPU. Según el blog de tecnología de Netflix, al utilizar un núcleo CUDA personalizado, el tiempo de entrenamiento de una red neuronal en una instancia cg1 se redujo de más de 20 horas a solo 47 minutos al procesar 4 millones de muestras.
En el mundo académico, la mayoría de los artículos que demostraban innovaciones en redes neuronales utilizaban de manera predeterminada la aceleración CUDA al realizar experimentos basados en GPU, lo que consolidó aún más su dominio en la emergente comunidad de aprendizaje profundo.
Mientras tanto, Qualcomm, Intel y Google se han asociado para ofrecer oneAPI como alternativa a CUDA de Nvidia, pero estos esfuerzos han fracasado en gran medida. La razón es simple: una vez que los desarrolladores invierten en el ecosistema CUDA, cambiar a otros marcos de GPU se convierte en un desafío abrumador. Requiere reescribir el código, aprender nuevas herramientas y, a menudo, volver a optimizar todo el proceso informático. Estos altos costos de cambio hacen que sea más práctico para muchas empresas y desarrolladores seguir confiando en los productos de Nvidia, en lugar de arriesgarse a explorar soluciones alternativas.
Incluso gigantes tecnológicos como Google, con recursos para invertir fuertemente en ASIC personalizados, han tenido dificultades para reemplazar a CUDA. En 2018, las GPU de Nvidia representaban más del 90% de la infraestructura TPUv2 de Google, a pesar de las importantes inversiones de la empresa en hardware personalizado.
En términos de tecnología de comunicaciones, la adquisición de Mellanox por parte de Nvidia ha generado preocupaciones en China, Estados Unidos y la UE.
A medida que los modelos de IA siguen creciendo en tamaño, los modelos de lenguaje grandes ahora requieren cientos de gigabytes, si no terabytes, de memoria solo para sus pesos de modelo. Por ejemplo, los sistemas de recomendación de producción implementados por Meta requieren docenas de terabytes de memoria para sus enormes tablas de incrustación. Una parte significativa del tiempo dedicado al entrenamiento o la inferencia para estos modelos grandes no se dedica a multiplicaciones de matrices, sino a esperar a que los datos lleguen a los recursos informáticos.
Para abordar este desafío, se ha introducido en la industria del entrenamiento de IA InfiniBand, un estándar de redes informáticas utilizado en informática de alto rendimiento que ofrece un rendimiento extremadamente alto y una latencia baja. Según el Instituto de Ingenieros Eléctricos y Electrónicos (IEEE), InfiniBand domina ahora las redes de IA y representa aproximadamente el 90 % de las implementaciones.
Mellanox ha sido el proveedor líder de tecnología InfiniBand. En 2019, Mellanox conectó el 59 % de las supercomputadoras TOP500, con un crecimiento interanual del 12 %, lo que demuestra su dominio y su continuo avance en la tecnología InfiniBand.
 Jensen Huang se reunió con el director ejecutivo de Mellanox, Eyal Waldman
Jensen Huang se reunió con el director ejecutivo de Mellanox, Eyal Waldman
Con la adquisición de Mellanox, Nvidia se asegura la “santísima trinidad” de la industria de la IA: dominio en chips GPU, herramientas de desarrollo y tecnologías de comunicación para computación distribuida. Esta adquisición fortalece aún más el monopolio de Nvidia en IA, creando un efecto de bola de nieve que hace cada vez más difícil que los competidores avancen.
Cuando la Administración de Regulación del Mercado de China aprobó la adquisición de Mellanox por parte de Nvidia en abril de 2020, impuso condiciones restrictivas adicionales. Entre ellas, se incluía la prohibición de que Nvidia combinara GPU y dispositivos de red, y la discriminación de los clientes que adquirieran estos productos por separado en términos de precio, función y servicio posventa. Sin embargo, en junio de 2022, Nvidia declaró explícitamente en el acuerdo de usuario de CUDA 11.6 que prohíbe el uso de software basado en CUDA en GPU de terceros. Esto obliga efectivamente a los desarrolladores que utilizan chips AMD e Intel a cambiar a las GPU de Nvidia, lo que llevó a China a iniciar una investigación sobre Nvidia la semana pasada por posibles violaciones de la ley antimonopolio.
A estas alturas, muchos de vosotros ya entendéis por qué China está investigando a Nvidia. Sin embargo, la pregunta sigue siendo: ¿por qué China recién ahora ha comenzado esta investigación, dos años después de que Nvidia supuestamente infringiera la ley? Este retraso puede atribuirse a tres factores clave.
En primer lugar, los fabricantes de chips de China finalmente han desarrollado la tecnología para desafiar a Nvidia.
La GPU Nvidia H100 se fabrica con el proceso N4 de TSMC, que está categorizado como un proceso de “5 nm” por la Hoja de Ruta Internacional para Dispositivos y Sistemas del IEEE. Mientras tanto, ASML solo tiene permitido vender máquinas DUV a China, que se utilizan principalmente para producir chips de 7 nm.
Según Bloomberg, SiCarrier, un desarrollador chino de equipos para la fabricación de chips que colabora con Huawei, obtuvo a finales de 2023 una patente relacionada con el patrón cuádruple autoalineado (SAQP). Este avance permite ciertos logros técnicos similares a los que se observan en la producción de chips de 5 nm. Business Korea argumentó en mayo que los chips fabricados con dichas técnicas costarían cuatro veces más que los producidos con litografía EUV, y las acciones de Huawei parecen desmentir esta afirmación. El 26 de noviembre, Huawei lanzó su Mate 70 Pro, con una versión de 1 TB a un precio de 7.999 CNY, el mismo precio que el Mate 60 Pro con especificaciones similares lanzado el año anterior.

El 9 de diciembre, el director ejecutivo de Huawei, Yu Chengdong, anunció públicamente que los chips de la serie Mate 70 están fabricados 100% en China. Technode informó que la CPU del Huawei Mate 70 Pro, el Kirin 9020, supera al Snapdragon 8+ Gen 1 de Qualcomm, que se lanzó en 2022 y se fabricó utilizando el proceso N4 de TSMC. Según fuentes internas, si bien el chip Kirin 9020 todavía puede utilizar un proceso de transistor de 7 nm, su tecnología de empaquetado avanzada ha mejorado enormemente la eficiencia informática.
El exitoso lanzamiento del Huawei Mate 70 Pro demuestra que los fabricantes de chips chinos ahora pueden producir chips que compitan con la tecnología de 5 nm de TSMC en grandes cantidades y a precios competitivos. Este logro también los posiciona para extender su experiencia a las GPU, siempre que adapten sus diseños para cumplir con los requisitos específicos de cada tipo de procesador. Este avance sugiere que los fabricantes de chips chinos se están acercando a la capacidad de producir GPU con un rendimiento de hardware comparable al H100 de Nvidia.
Además, el Financial Times informa de que el mayor fabricante de chips de China, SMIC, ha instalado nuevas líneas de producción de semiconductores en Shanghái, con el objetivo de producir chips de 5 nm. Aunque los chips de 5 nm siguen estando una generación por detrás de los actuales chips de 3 nm, la medida demostraría que la industria de semiconductores de China sigue haciendo progresos graduales, a pesar de los controles de exportación de Estados Unidos.

En segundo lugar, las empresas chinas de IA están cada vez más posicionadas para reducir su dependencia de CUDA.
Las empresas estadounidenses como Google y Meta siguen dependiendo en gran medida de CUDA porque ofrece el mejor rendimiento de aceleración para el chip H100 de Nvidia, que domina el mercado de hardware de IA. Sin embargo, la Ley CHIPS and Science, firmada por el presidente Biden, prohibió a Nvidia exportar chips H100 a empresas chinas después de 2022. Esta restricción ha obligado a los gigantes tecnológicos chinos como Baidu y Tencent a explorar alternativas, incluidas las GPU de AMD y los chips GPU desarrollados en el país, lo que reduce efectivamente su dependencia del ecosistema CUDA de Nvidia.
Además, Moore Threads, una empresa china de diseño de GPU, lanzó su arquitectura de sistema unificado Moore Threads, MUSA, el 5 de noviembre. La arquitectura MUSA, un serio rival de CUDA, proporciona una plataforma informática de alto rendimiento, flexible y altamente compatible que admite varias tareas de computación paralela, incluida la computación de IA, la representación de gráficos, las aplicaciones multimedia y la simulación física. La empresa también proporciona una gran cantidad de herramientas y bibliotecas de desarrollo, como MUSA SDK, bibliotecas de aceleración de IA, bibliotecas de comunicación, etc., para ayudar a los desarrolladores a desarrollar y optimizar mejor las aplicaciones. Además, MUSA es compatible con la interfaz de pila de software de CUDA, lo que facilita significativamente el proceso de portabilidad de aplicaciones y reduce el costo para las empresas de alejarse de los productos de Nvidia.
 La GPU MTT S4000 AI de Moore Threads ya estará disponible en diciembre de 2023
La GPU MTT S4000 AI de Moore Threads ya estará disponible en diciembre de 2023
En tercer lugar, la tecnología InfiniBand se está volviendo obsoleta en comparación con los avances de Ethernet chinos.
Si bien InfiniBand domina actualmente las redes de IA con aproximadamente el 90 % de las implementaciones, IEEE informa que Ethernet está surgiendo como un fuerte contendiente para los clústeres de IA. Por ejemplo, InfiniBand a menudo queda por detrás de Ethernet en términos de velocidades máximas. El último conmutador Quantum InfiniBand de Nvidia alcanza los 51,2 Tb/s con puertos de 400 Gb/s, mientras que Ethernet alcanzó los 51,2 Tb/s hace casi dos años y ahora admite velocidades de puerto de hasta 800 Gb/s.
Uno de los desafíos para la adopción de Ethernet ha sido su incapacidad para manejar las enormes cargas de trabajo del entrenamiento de IA y otras aplicaciones de computación de alto rendimiento (HPC). Los altos niveles de tráfico en los centros de datos pueden generar cuellos de botella, lo que provoca problemas de latencia que lo hacen inadecuado para estas tareas.
Sin embargo, el 27 de septiembre, durante la Conferencia de Poder Computacional de China de 2024, la estatal China Mobile y otros 50 socios presentaron Global Scheduling Ethernet (GSE), un nuevo protocolo de red diseñado para manejar grandes volúmenes de datos y proporcionar transferencias de alta velocidad adaptadas a la IA y otras cargas de trabajo de HPC.

Desde que Nvidia adquirió Mellanox en 2019, ya no hay proveedores independientes de productos InfiniBand. En cambio, Ethernet cuenta con una amplia gama de proveedores en todo el mundo. Si China Mobile logra promover con éxito la tecnología Ethernet como reemplazo de InfiniBand en aplicaciones de IA, podría brindar a las empresas de IA de todo el mundo acceso a proveedores locales, lo que podría reducir los costos y fomentar la competencia.
China no es el único país que desafía el monopolio de Nvidia, pero sí es el más decidido y hábil. Gracias a las sanciones estadounidenses, a los propios avances tecnológicos de China y a un vasto mercado interno, China se ha convertido en uno de los pocos países con una independencia y competitividad significativas en hardware, software y tecnología de las comunicaciones. Y lo que es más importante, estas empresas tecnológicas no son propiedad exclusiva del Estado, sino que están impulsadas por el ingenio y los esfuerzos del pueblo chino.
En octubre de 2024, China contará con 1.100 millones de usuarios de Internet, lo que representa el 20% de la población total en línea del mundo. Cuando el presidente Biden prohibió a las empresas chinas comprar los chips y algoritmos estadounidenses más avanzados, fue la demanda de estos 1.100 millones de usuarios (que participan en actividades como ver videos cortos, jugar y comprar en línea) lo que impulsó a las empresas tecnológicas chinas a buscar la autosuficiencia. Según las estadísticas oficiales chinas, en 2023, el tamaño del mercado de la economía digital de China alcanzó los 53,9 billones de yuanes.
Sin duda, Europa y el Sur Global tienen mentes tan brillantes como la de China. Sin embargo, dado que Google y Meta dejan poco espacio para que surjan competidores en estas regiones, nunca podrán contar con el apoyo de los usuarios europeos y del Sur Global para deshacerse del dominio de Nvidia. El libre mercado es genial, pero si solo lo apoyas cuando se adapta a tus necesidades, es posible que no funcione como debería.
GACETA CRÍTICA, 16 DE DICIEMBRE DE 2024

Deja un comentario